Fonctions avancées : paramétrage des exports tabulés paramétrables
- A savoir avant de commencer
- Paramètres généraux d'un modele etp
- Export d'un champ
- Concaténation libre de champs dans une seule colonne
- Export des champs d'un bloc répétable
- Export des via des liens par héritage (référence)
- Autres paramétrages
page en cours de construction
A savoir avant de commencer
L'export de données muséologiques vers un tableur met en évidence la particularité de leur organisation technique.
Pour pouvoir répondre aux exigence scientifiques de leur description, il n'est pas possible d'utiliser des grilles de saisie de type tableur, avec juste des lignes et des colonnes, il faudrait un nombre inifini de colonnes.
Les grilles de saisie dans Flora,s'appuient donc sur deux notions extrèmement puissantes : les blocs répétables et les champs multivalués
Comprendre les blocs répétables et les champs multivalués
Ces deux notions sont fondamentales en informatique muséologique. Elles permettent de s'affranchir des limites techniques imposées par les bases de données traditionnelles (tables de jointures).
Historiquement on appelait cela des bases de données XML, aujourd'hui (entre informaticiens) on parlerait plutôt de NoSql
Ces notions sont fonctionnellement très puissantes en saisie, mais elles imposent quelques rêgles quand on veut remettre les données "à plat" pour des affichages, des impressions, des exports.
Exemple :
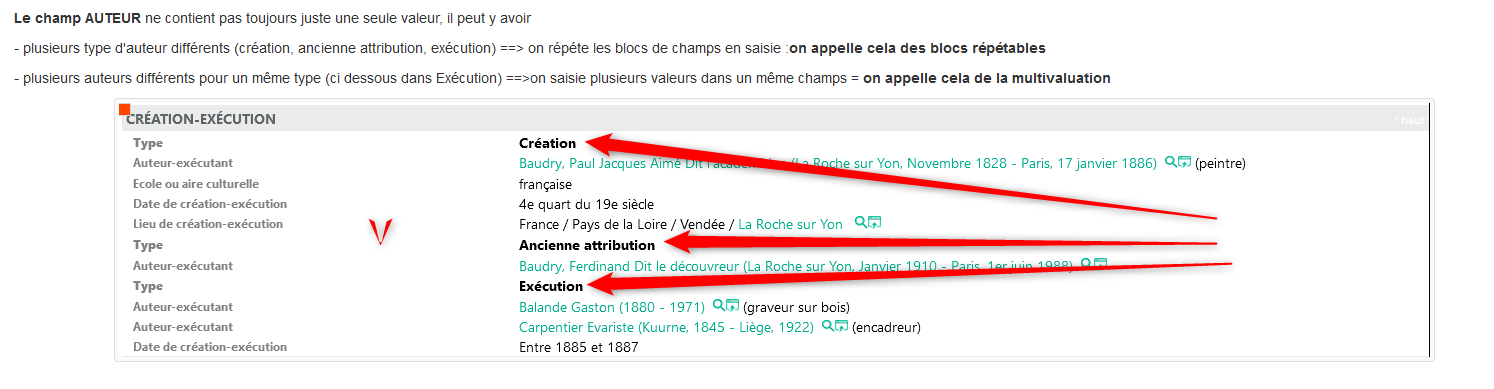
Dans un export CSV pour excel ou calc,:
- Par défaut les champs multivaluées seront concaténés avec un séparateur virgule+espace entre chaque valeur... donc ça marche tout seul
- Exemple : si je demande à exporter juste le champ Auteuir-Exécutant, dans une colonne je récupererai les 4 auteurs ci dessus, séparés par virgule+espace, mais sans savoir de quel "type" ils dépendent
- Par contre, pour les blocs répétables, comme il n'est pas possible de générer un nombre de colonnes variables dans l'export, en général on concaténera les champs d'un même blocs, puis les différentes occurences d'un même bloc dans une seule et unique Colonne
- Exemple : si je demande à exporter Le bloc "Création-exécution" dans une colonne ,je devrai paramétrer le mode de concaténation des différents champs qu'il contient, aisni que le mode de concaténation de chaque occurence de bloc. de facto j'aurai besoin de pouvoir paramétrer des séparateurs, ajouter des libellés de champs....bref "formater" la conaténation des blocs
Paramètres généraux d'un modele etp
dans l'entête du fichier etp les paramétres suivants pourront etre défini
<table
name="MUS_STRATIGRAPHIE"
nom interne de la table à exporter
charset="ISO-8859-1"
jeu de caractere du fichier résultat
Attention, il est préférable de conserver ce paramétre car les publications réalisées sont ensuiote déclarées avec un type mime et une extension CSV, de manière a étre ouvertes automatiquement dans Excel par un double clic sur le nom de fichier
separator="\t"
Le séparateur tabulation est préférable car il est certain qu'il n'a pas été saisi dans une des notices exportées, la publication génére donc un fichier CSV mais dont les sépareurs de colonnes sont des tabulations
compressChar=" ; "
caracteres utilisé lors de concaténation automatiques de données dans des blocs répétables
newLine="\r\n"
caracteres délimitant les changement d'enregistrement \r=chr(13) |n=chr(10)
multiValueSeparator=', '
caracteres utiliser pour concaténer les données des champs multivaluées virgule+espace
valueDelimiter='"'>
ne pas modifier, permet d'englober les contenus de colonne contenant des \n ou des apsotrophes pour éviter und écalage à l'oiuverture du fichier csv publié
Exemple :
Export d'un champ
Les exemples ci aprés sont issus de l'export CSV de la table Stratigraphie, mais sont transposables dans toutes les tables de Flora
Formatage automatique selon le mode de saisie
Par défaut, Flora mettra en forme l'export des champs en fonction de leur mode de saisie de la manière suivante
Champs texte libre sur une seule ligne
Exemple :

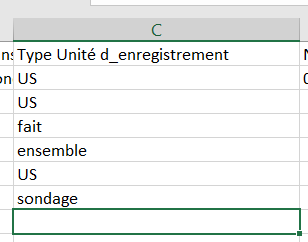
La ligne ci dessous génèrera une colonne dont le titre sera égal au label et les contenus alimentés par le champs cité dans name
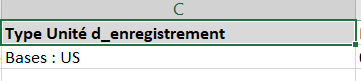
<field name='TYPE_UE' label='Type Unité d_enregistrement '/>
- name : nom interne du champ dans la table Flora
- label : intitulé qu'aura la colonne dans le fichier csv
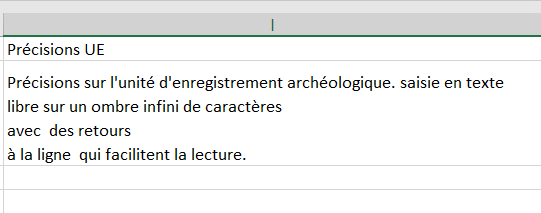
Champs texte libre multiligne (avec retours à la ligne)

<field name='PRECISION_UE' label='Précisions UE '/> aura pour résultat
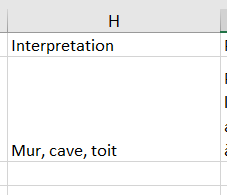
Champs multivalués liés à des listes, thésaurus ou table d'autorité

<field name='INTERPRETATION' label='Interpretation'/> aura pour résultat
Formatages personnalisés sur un champ
- dataBefore : separateur avant la donnee du champ, répété en cas de multivaluation (Chaine vide si non defini)
- dataMultiValueSeparator : separateur de champ multivalue (Si non defini c'est celui qui est defini dans l'attribut multiValueSeparator du tag 'table', ou si non defini c'est '/' slash par defaut)
- dataAfter : separateur apres la donnee du champ répété en cas de multivaluation (Chaine vide si non defini)
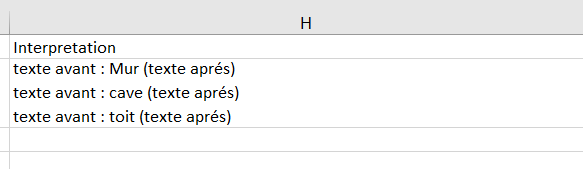
Exemple : <field name='INTERPRETATION' label='Interpretation' dataBefore="texte avant " dataAfter=" texte aprés" dataMultiValueSeparator=" ; "/>

<field name='INTERPRETATION' label='Interpretation' dataBefore="texte avant : " dataAfter=" (texte aprés)" dataMultiValueSeparator="\n"/>
Exporter une valeur constante
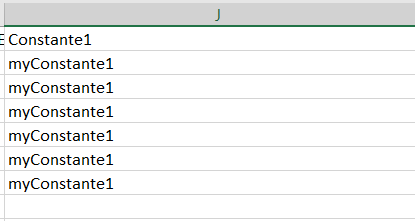
Toutes les lignes auront la même valeur dans la colonne
<constant name="C1" label="Constante1" dataDefValue="myConstante1" />
Exporter un ou plusieurs champs d'une table d'autorité liée
par défaut, les champs liés à des table d'autorité s'exportent avec la concaténation standard des champs de la table liée (dans Flora on appelle ça le digest de la table, il est défini dans le fichierconf/local/musee/db/A.musee.xml digest ou link-digest s'il est défini).
De facto, tout se retrouve dans une seule et même colonne
Exemple avec le champ qui lie la Table Stratigraphie à la Table Opération
A minima, l'export sera réalisé ainsi, avec le champ DISPLAY_OPERATION qui n'est pas répété ni multivalué. c'est un champ caché de Flora qui ne contient que la première de toutes les opérations potentiellement liées à la notice stratigraphie
<field name='DISPLAY_OPERATION' label='Opération1'/>

il est donc possible "d'éclater" les champs de la table liée par colonne via le linked_field. Chaque champ exportée de la table liée sera positionné dans un colonne dédiée. de cette manière on n'est p^lus bridé par le digest ou le link-digest
<linked_field name='DISPLAY_OPERATION'>
<field name='NUM_IDENTIFIANT' label="Identifiant Opération" />
<field name='TYPE_OPERATION' label="Type opération" dataBefore="(" dataAfter=")" />
</linked_field>

SI on utilise le champ OPERATION (dans le bloc découverte de la grille de saisie), IL est possible d'y saisir plusieurs Opérations liées
Dans ce cas, le découpage sera respecté dans chacune des colonnes, mais il ny' aura toujours que 2 colonnes
<linked_field name='OPERATION'>
<field name='NUM_IDENTIFIANT' label="Identifiant(s) Opération" />
<field name='TYPE_OPERATION' label="Type opération(s)" dataBefore="(" dataAfter=")" />
</linked_field>



Concaténation libre de champs dans une seule colonne
Dans de nombreux cas il sera nécéssaire de regrouper différents champs de la table dans une seule et même colonne
Exemple : concaténer tous les champs de Données intrinsèque d'une notice Stratigraphie dans une seule colonne
De facto il sera judicieux
- de ne pas perdre les libellés de champs (on les indiquera dans dataBefore)
- de n'avoir des séparateurs de champs que si un au moins des champs précédents est non vide...sinon le contenu de la colonne commencera par un séparateur (on les indiquera dans dataJoinSeparator)
A minima
on va donc créer une "boite" qui va assembler les données de la colonne en concaténant les champs cités
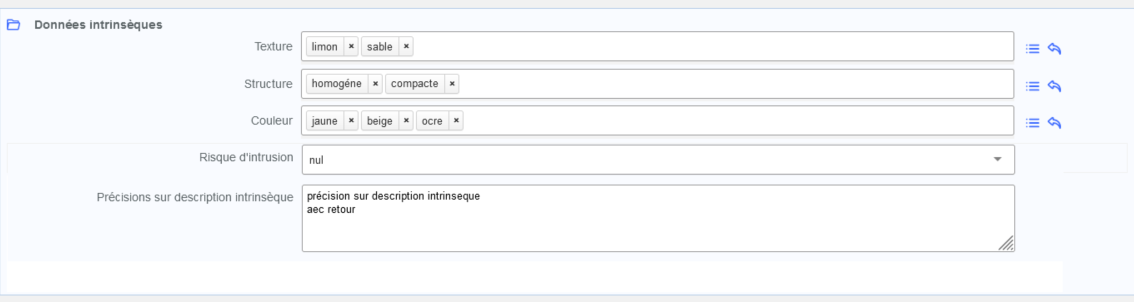
<concat name="donnees_descr_intr label="Données descriptives intrinsèques">
<field name='TEXTURE' dataBefore='Texture '/>
<field name='STRUCTURE' dataBefore='Structure ' dataJoinSeparator=" ; "/>
<field name='COULEUR' dataBefore='Couleur ' dataJoinSeparator=" ; "/>
<field name='RISQUE_INTRUSION' dataBefore='Risque d_intrusion ' dataJoinSeparator=", " />
<field name='DESCRIPTION_INTRINSEQUE' dataJoinSeparator="\n"/>
</concat>

Ajout de données avant - aprés
Cette "boite" concat est vue comme un "groupe" de données. a ce titre il est possible de lui adjoindre les paramétres suivants
- groupDataBefore : donnee avant le groupe
- groupDataAfter : donnee apres le groupe
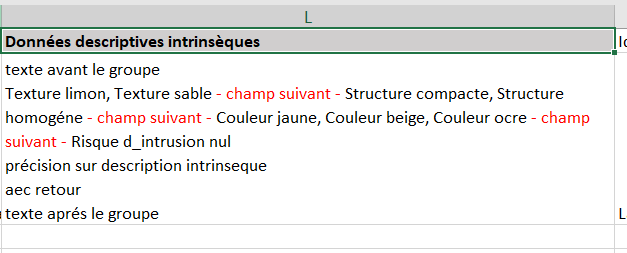
<concat name="donnees_descr_intr label="Données descriptives intrinsèques"
groupDataBefore="texte avant le groupe\n"
groupDataAfter="\ntexte aprés le groupe"
>
<field name='TEXTURE' dataBefore='Texture '/>
<field name='STRUCTURE' dataBefore='Structure ' dataJoinSeparator=" ; "/>
<field name='COULEUR' dataBefore='Couleur ' dataJoinSeparator=" ; "/>
<field name='RISQUE_INTRUSION' dataBefore='Risque d_intrusion ' dataJoinSeparator=", " />
<field name='DESCRIPTION_INTRINSEQUE' dataJoinSeparator="\n"/>
</concat>
A noter les \n qui se transforment en retour à la ligne dans la colonne et le datajoinSeparator qui poermet de choisir si on veut un point virgule ou un retour ligne entre chaque champs
Ajout de données par défaut entre les champs du groupe
Dans l'exemple ci-aprés, on a positionnés les séparateurs de champs dans chacun des champs avec le DataJoinSeparator
on pourrait aussi définir une valeur par défaut pour tous les champs du groupe, le subGroupDataSeparator ce qui simplifie le paramétrage
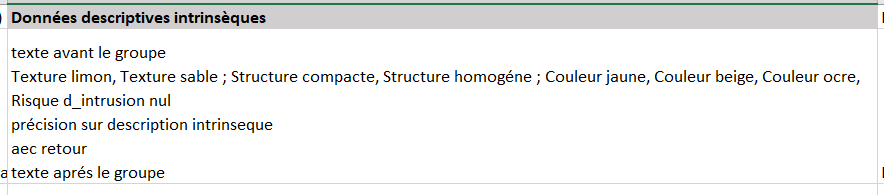
<concat name="donnees_descr_intr" label="Données descriptives intrinsèques"
groupDataBefore="texte avant le groupe\n"
groupDataAfter="\ntexte aprés le groupe"
subGroupDataSeparator=" - champ suivant - "
>
<field name='TEXTURE' dataBefore='Texture '/>
<field name='STRUCTURE' dataBefore='Structure ' />
<field name='COULEUR' dataBefore='Couleur ' />
<field name='RISQUE_INTRUSION' dataBefore='Risque d_intrusion ' />
<field name='DESCRIPTION_INTRINSEQUE' dataJoinSeparator="\n"/>
</concat>
A noter : comme on a conservé un DataJoinSeparator sur le dernier champ (car on voulait un retour ligne dans ce cas),le subGoupDAtaSeparator ne s'y applique pas car ce n'est qu'une valeur par dfaut
résultat obtenu : Nous avons mis en rouge le subGoupDataSeparator pour bien comprendre qu'il s'applique "à chaque champ", mais pas à chaque valeur d'un champ multivalué.
Dans notre jargon technique on dira que le field dans un concat est un sous-groupoe
Export des champs d'un bloc répétable
Tout ce qui est décrit ci dessus sera exploitable dans les exports de bloc répétable.Un export de bloc répétable pourra contenir des fields, des linked_field, des concats, des constantes
Globalement il ressemblera beaucoup à un concat, à la différence prés qu'un concat ne se joue qu'une seule fois, alors que le bloc de champs se jouera dans l'export autant de fois qu'il y a de groupe saisis dans la notice courante
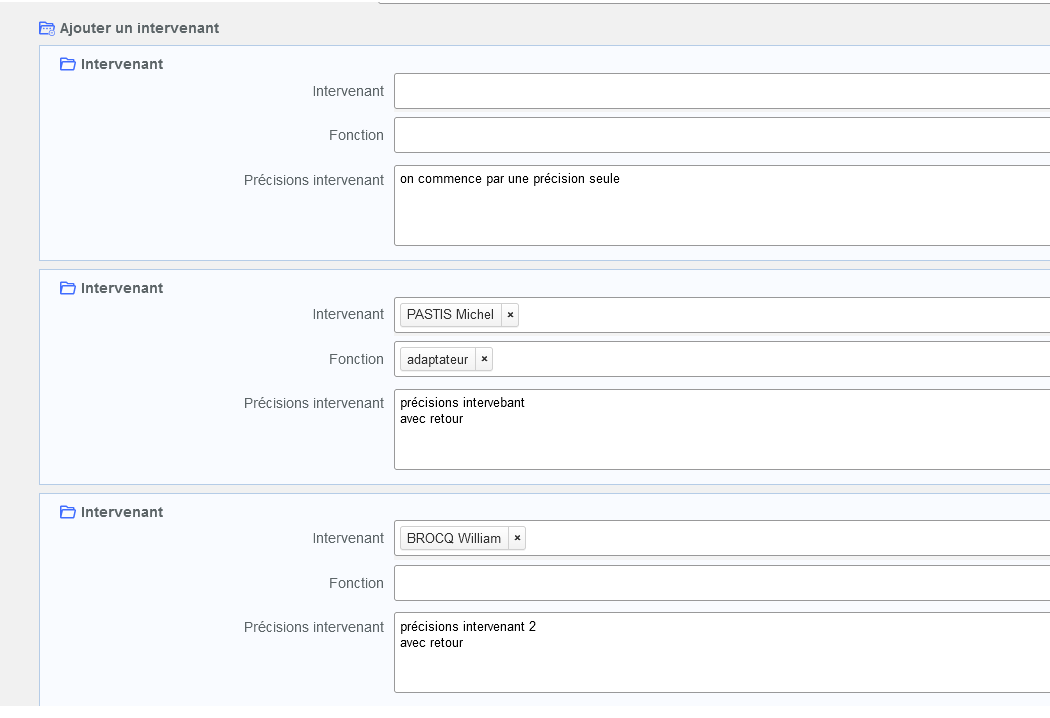
Exemple avec un bloc de champ répétable contenant 3 champs avec une saisie lacunaire (il est rare que tous les champs soient remplis dans un bloc)
le paramétrage de l'export sera défini tel que :
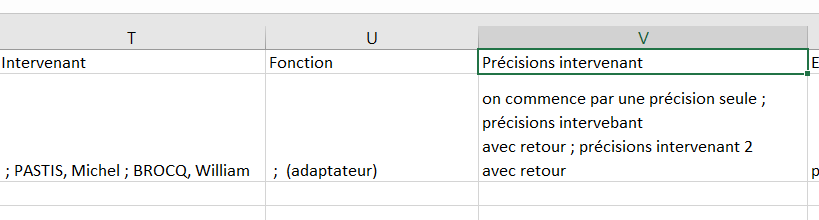
<group_field name="INTERVENANT"
groupDataType = "group"
label = "Intervenants"
groupDataSubGroupSeparator = "\n\n"
>
<field name='PERSONNE_INTERVENANT' label='Intervenant'/>
<field name='FONCTION_INTERVENANT' label='Fonction ' dataBefore=" (" dataAfter=")"/>
<field name='PRECISION_INTERVENANT' label='Précisions intervenant ' dataJoinSeparator="\n"/>
</group_field>
et génerera la colonne ci dessous
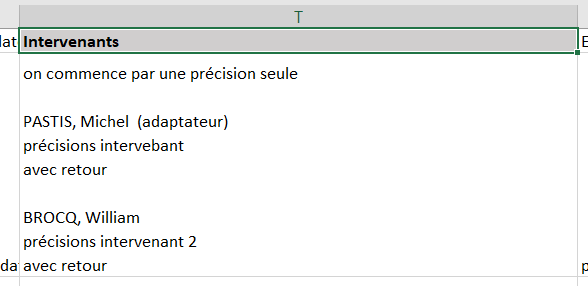
La nouveauté ici c'est le groupDataSubGroupSeparator qui permet de définir le séparateur qui s'exporte entre chaque sous-groupe (deux sauts de ligne \n dans le cas présent)
Il est possible de choisir un type= "sous groupe"
<group_field name="INTERVENANT"
groupDataType = "SubGroup"
label = "Intervenants"
>
<field name='PERSONNE_INTERVENANT' label='Intervenant'/>
<field name='FONCTION_INTERVENANT' label='Fonction ' dataBefore=" (" dataAfter=")"/>
<field name='PRECISION_INTERVENANT' label='Précisions intervenant ' dataJoinSeparator="\n"/>
</group_field>
Dans ce cas chaque élément du groupe générera sa propre colonne, donc ce n'est pas trés différent d'avoir positionné ces 3 champs directement dans le template etp, sans tenir compte du group_field, ou bien directement dans un concat, mais avec la contrainte de ne pouvoir y inclure que des champs du bloc répétable courant
A noter que pour les type=SUbGroup le label du group_field est ignoré et que ce sont les labels de chaque élément qui sont pris en compte dans les intitulé de colonne
Paramétrages complémentaires pour les blocs répétables
il est possible d'inclure aussi dans un group_field
- une concaténation formalisée des champs du bloc répétable courant via le tag concat
- des champs des notices liées a un des champs du bloc via le tag 'linked_field'
- des notices qui référencent la notice courante : tag 'reference' pour les liens parent/enfants. ce tag est étudié plus loin dans l'article
Ajout de données avant - après chaque sous-groupe
- subGroupDataBefore : séparateur avant les données d'un sous-groupe (Chaine vide si non défini)
- subGroupDataSeparator : séparateur entre les données d'un sous-groupe (Espace si non défini)
- subGroupDataAfter : séparateur après les donnes d'un sous-groupe (Chaine vide si non défini)
Ajout de données avant - après le groupe
Uniquement si groupDataType="group" car la colonne unique contiendra une concaténation de tous les sous-groupes en un seul groupe
- groupDataBefore : séparateur avant les données du groupe (Chaine vide si non défini)
- groupDataSubGroupSeparator : séparateur entre les sous-groupes (' / ' espace slash espace si non défini)
- groupDataAfter : séparateur après les données du groupe (Chaine vide si non défini)
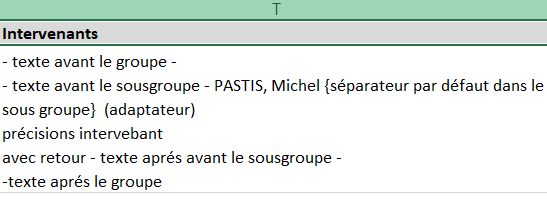
Exemple global
<group_field name="INTERVENANT"
groupDataType = "group"
label = "Intervenants"
groupDataBefore = "- texte avant le groupe -\n"
groupDataSubGroupSeparator = "\n{séparateur par défaut entre les sous groupe}\n"
groupDataAfter = "\n-texte aprés le groupe"
subGroupDataBefore = "- texte avant le sousgroupe - "
subGroupDataSeparator = " {séparateur par défaut dans le sous groupe} "
subGroupDataAfter = " - texte aprés avant le sousgroupe -"
>
<field name='PERSONNE_INTERVENANT' label='Intervenant'/>
<field name='FONCTION_INTERVENANT' label='Fonction ' dataBefore=" (" dataAfter=")"/>
<field name='PRECISION_INTERVENANT' label='Précisions intervenant ' dataJoinSeparator="\n"/>
</group_field>

Filtre sur les données du groupe
D'un certaine manière un bloc répétable peut être considéré comme une table liée embarquée dans la notice courante
Il sera donc possible de filtrer les occurences d'un bloc répatable en fonction du contenu d'un ou de plusieurs de ces champs avec une syntaxe de type Sql [NOM_DU_CHAMP] opérateur [VALEUR]. De facto seuls les blocs répondant à cette condition seront exportés , les autres seront ignorés
Masquer des sous-groupes
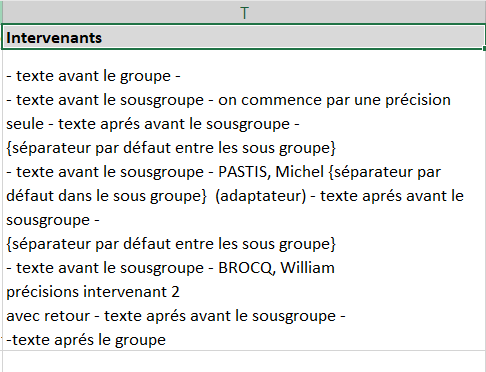
Exemple : je voudrais n'exporter que les blocs Intervenants dont le champ Fonction est rempli
<group_field name="INTERVENANT"
groupDataType = "group"
label = "Intervenants"
subGroupDataFilter = "(FONCTION_INTERVENANT != null)"
groupDataBefore = "- texte avant le groupe -\n"
groupDataSubGroupSeparator = "\n{séparateur par défaut entre les sous groupe}\n"
groupDataAfter = "\n-texte aprés le groupe"
subGroupDataBefore = "- texte avant le sousgroupe - "
subGroupDataSeparator = " {séparateur par défaut dans le sous groupe} "
subGroupDataAfter = " - texte aprés avant le sousgroupe -"
>
<field name='PERSONNE_INTERVENANT' label='Intervenant'/>
<field name='FONCTION_INTERVENANT' label='Fonction ' dataBefore=" (" dataAfter=")"/>
<field name='PRECISION_INTERVENANT' label='Précisions intervenant ' dataJoinSeparator="\n"/>
</group_field>
Seul le bloc n° 2 est exporté
Masquer des champs dans un sous-groupe
Exemple : je voudrais n'exporter que les blocs Intervenants dont le champ Fonction est rempli
<group_field name="INTERVENANT"
groupDataType = "group"
label = "Intervenants"
groupDataBefore = "- texte avant le groupe -\n"
groupDataSubGroupSeparator = "\n{séparateur par défaut entre les sous groupe}\n"
groupDataAfter = "\n-texte aprés le groupe"
subGroupDataBefore = "- texte avant le sousgroupe - "
subGroupDataSeparator = " {séparateur par défaut dans le sous groupe} "
subGroupDataAfter = " - texte aprés avant le sousgroupe -"
>
<field name='PERSONNE_INTERVENANT' label='Intervenant'/>
<field name='FONCTION_INTERVENANT' label='Fonction ' dataBefore=" (" dataAfter=")"/>
<field name='PRECISION_INTERVENANT' label='Précisions intervenant ' dataJoinSeparator="\n" inputGroupFieldFilter="(FONCTION_INTERVENANT is null)"/>
</group_field>
dans le lLoc n° 2 le cchamp PRECISIONS_INTERVENANT n'est pas exporté
Limiter le nombre de sous-groupe exportés
subGroupDataMultMaxi="1" fera en sorte que seul le premier bloc sera exporté
subGroupDataMultMaxi="4" fera en sorte que seuls les 4 premiers blocs seront exportés
Imbrication de groupes
Il n'y a pas de limite au nombre de niveaux imbriqués, il est donc possible de "suivre" la strucre hiérarchique d'un bloc répétable
Exemple avec les lots archéo
<group_field name="LOT_ELEMENT"
groupDataType = "group"
label = "Archéo - lot"
groupDataSubGroupSeparator = "\n\n"
subGroupDataSeparator = ""
>
<field name='DOMAINE_ELEMENT' />
<field name='DENOMINATION_ELEMENT' dataJoinSeparator=" ; " />
<field name='APPELLATION_ELEMENT' dataJoinSeparator=" ; " />
<field name='TYPOLOGIE_ELEMENT' dataJoinSeparator=" ; " />
<group_field name="LOT_DENOMBREMENT"
groupDataType = "group"
label = "Element - lot"
groupDataBefore ="\n"
groupDataSubGroupSeparator = " ; "
subGroupDataSeparator = ""
>
<field name='LOT_TYPE_ELEMENT' dataBefore="" />
<field name='LOT_NB_FRAGMENTS' dataBefore=" (" dataAfter=")"/>
<field name='LOT_QTE_ESTIMEE' dataBefore=" (" dataAfter=")"/>
</group_field>
<field name='ELEMENT_NB_FRAGMENT' dataJoinSeparator="\nNb Tot. " />
<field name='ELEMENT_NMI' dataJoinSeparator="\nNMI " />
<field name='ELEMENT_POIDS' dataJoinSeparator="\nPoids " dataAfter=" g" />
<field name='ELEMENT_PRECISION' dataJoinSeparator="\n" />
</group_field>

Export des via des liens par héritage (référence)
Des notices qui référencent la notice courante : tag 'reference'
Actuellement ce tag s'appuie sur l'index Q des liens inverses entre table (sans précision du champ qui établit le lien).
ON ne pourra donc pas l'utiliser pour faire remonter la liste des notices filles liées à une notice méré car dans MUS_BIEN plusieurs champs sont liés à MUS_BIEN
il permettra par exemple de
lister les notices récolement ou constat d'état liées à un bien dans un export des biens
<?xml version="1.0" encoding="ISO-8859-1"?>
<export-conf>
<table name="MUS_BIEN" charset="ISO-8859-1" separator="\t" compressChar="\n" newLine="\r\n" multiValueSeparator=', ' valueDelimiter='"'>
<field name='UNIQUE_KEY' label='Unique Key'/>
<field name='MUSEE' label='Préfixe'/>
<field name='NUM_INVENTAIRE' label='Numéro D'inventaire'/>
<reference source='musee' table='MUS_RECOLEMENT'
groupDataType = "subGroup"
label = "Récolements et localisations"
subGroupDataBefore = ""
subGroupDataSeparator = ", "
subGroupDataAfter = "" >
<field name='ETAT_MODIFIE_LE' label='Réalisé le/>
<field name='ETAT_MODIFIE_PAR' label='Réalisé par/>
<linked_field name='EMPLACEMENT' label='Emplacement théorique'>
<field name='LABEL_PARENT' label='Empl. référence hiéra' display='true'/>
</linked_field>
<linked_field name='EMPLACEMENT_NOUVEAU' label='Emplacement nouveau'>
<field name='LABEL_PARENT' label='Empl. référence hiéra' display='true'/>
</linked_field>
</reference>
Il serait théoriquement possible de filtrer récolement
subGroupDataFilter = "(ETAT_AVANCE_RECOL != '6')"
et relocalisations
subGroupDataFilter = "(ETAT_AVANCE_RECOL = '6')"
lister les notices exemplaires liées à une notice bib
<?xml version="1.0" encoding="ISO-8859-1"?>
<export-conf>
<table name="UNIMARC" charset="ISO-8859-1" separator="\t" compressChar="||" newLine="\r\n" >
....
<linked_field name='712a'>
<field name='210a' label='712a-Nom' display='true'/>
<field name='210b' label='712a-Subdivision' display='true'/>
</linked_field>
<reference source='system' table='ICOMM_ITEM'
groupDataType = "subGroup"
label = "Exemplaires"
subGroupDataBefore = "{ "
subGroupDataSeparator = ", "
subGroupDataAfter = "}" >
<field name='STATUS' label='EX-STATUS_DISPLAY' display='true'/>
<field name='CODE' label='Ex-CODE' display='false'/>
<field name='SITE' label='Ex-Bibliothèque' display='true'/>
</reference>
lister les biens liés à un colis
<?xml version="1.0" encoding="ISO-8859-1"?>
<export-conf>
<table name="MUS_COLIS" charset="ISO-8859-1" separator="\t" compressChar="\n" newLine="\r\n" multiValueSeparator=', ' valueDelimiter='"'>
<field name='ETAT_MODIFIE_LE' label='Etat modifié le'/>
<field name='ETAT_AVANCE_COLIS' label='Etat d_avancement'/>
<field name='UNIQUE_KEY' label='Numéro de Code'/>
<linked_field name='LOCATION_REFERENCE' label='Emplacement de référence'>
<field name='LABEL_PARENT' label='Empl. référence hiéra' display='true'/>
</linked_field>
<linked_field name='LOCATION_CURRENT' label='Localisation actuelle '>
<field name='LABEL_PARENT' label='Loc. Actuelle hiéra' display='true'/>
</linked_field>
<reference source='musee' table='MUS_JOIN_COLIS'
groupDataType = "subGroup"
label = "Biens liés"
subGroupDataBefore = ""
subGroupDataSeparator = ", "
subGroupDataAfter = "" >
- <linked_field name='BIEN' label='Bien'>
<field name='DISPLAY' label='Bien' display='true'/>
</linked_field>
</reference>
- <linked_field name='BIEN' label='Bien'>
<reference source='musee' table='MUS_JOIN_COLIS_MOUV'
groupDataType = "subGroup"
label = "Biens en mvmnt liés"
subGroupDataBefore = ""
subGroupDataSeparator = ", "
subGroupDataAfter = "" >
<linked_field name='MOUVEMENT_BIEN' label='Bien'>
<field name='DISPLAY' label='Bien' display='true'/>
</linked_field>
</reference>
Autres paramétrages
Conversions de dates et datations
dataDateFormatDisplay='yyyy-MM-dd'
dataDateFormatDisplay='yyyy'
.....
Cela fonctionne pour les champs dates, time et datation
time <field name='CREATE_DATE' label='Saisi le' dataDateFormatDisplay='yyyy-MM-dd'/>
date <field name='ETAT_MODIFIE_LE' label='Etat modifié le ' dataDateFormatDisplay='yyyy-MM-dd'/>
datation <field name='DATATION_BIEN_DEBUT' dataDateFormatDisplay='yyyy' /> Pour l'instant les dates Avant Jésus-Christ ne sont pas mentionnées comme telmes quand on applique cette conversion
valeur par défaut
dataDefValue="maValeurtextuelle"
si le field, linked_field, concat, group_feld est vide, c'est cette valeur qui sera exportée
Exemple : utilisé dans l'export e-recolnat pour avoir par défaut la colonne langue = FR sans devoir la saisir dans toutes les notices. si le champ Langue de notice est non vide il écrasera la dataDefValue
Données textuelles ajoutées en multilangue
Flora gére des fichiers de mots clés pour la traduction des labels textuels dans les différentes languies (dans les fichiers *.properties)

ces mots clés peuvent etre utilisés dans toutes les valeurs textuelles posées dans les tags
Exemple
<field name='TYPE_UE' label='Type Unité d_enregistrement ' dataBefore='${menu.label.inventory} : '/>
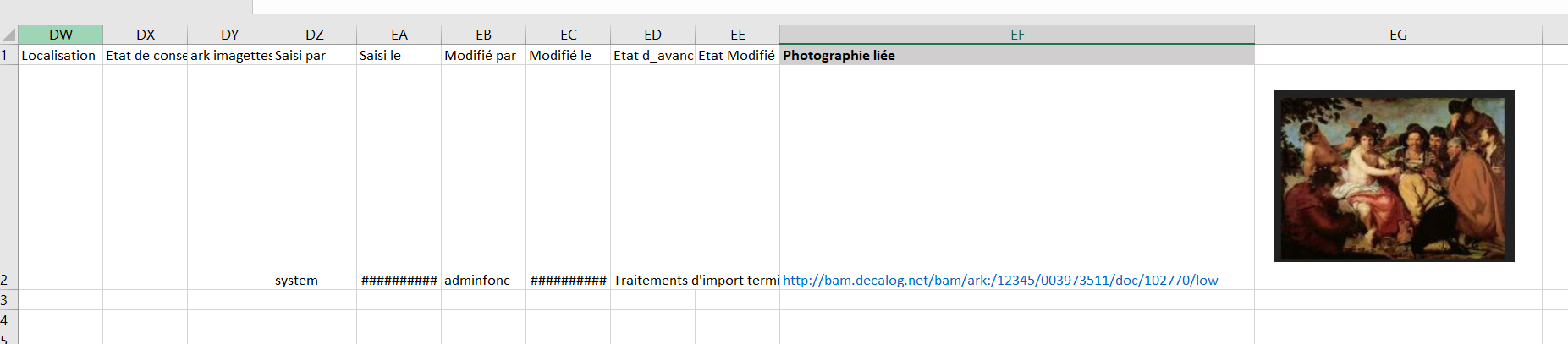
Export des liens ark vers les images
Il est toujorus délicat d'incorporer les images en tant que telles dans une colonne excel ou calc car cela rend enuite le fichier difficile à manipuler, et dans le cas de calc elels ne suivent pas les tris réalisés sur le tableau ce qui rend les onnées incohérentes
de plus sur de gros volumes cela peut générer des fichiers de trop grande taille, surtout si on intégre les images originales au liue de se contenter des imagettes
Nous avons donc choisi de publier les images dans les tablmeurs vai des liens ark
la colonne devra donc etre paramétrée ainsi
name="PHOTO_INV" =nom du champ contenant le lien vers la phototheque (si l'export concerne MUS_PHOTO on indiquera UNIQUE_KEY)
subGroupDataMultMaxi="1" Nombre de notices photos lues, il est recommandé de ne mettre qu'un seul lien ark car de facto le lien sera automatiquemenrt clicable dans excel (aprés avoir cliqué dans la cellule)
dataMultMaxi="1" Nombre de fichiers images lus par notice photo, il est recommandé de ne mettre qu'un seul lien ark car de facto le lien sera automatiquemenrt clicable dans excel (aprés avoir cliqué dans la cellule)
dataBefore="${flora-url}/ark:" reprendra automatiquement la racine de l'url de votre applucation flora. SI cette url est accessible par internet et que vous avecz activé le service ark sur votre application, la visualisation des uimages sera possible sur tout poste de travail connecté à internet
dataAfter="/low" renverra l'imagette,
- si on met /medium on aura un fichier de 800 pixels,
- si on met /high on aura l'image originale non redimensionnées (mais pas la THDEF)
<linked_field name="PHOTO_INV"
label="Image"
inputRecordFilter=""
groupDataType="group"
subGroupDataSeparator=" ~ "
subGroupdataMultiValueSeparator="|"
subGroupDataMultMaxi="1"
>
<class_extractor
extractorClassName="com.ezida.services.musee.extractor.MusPhotoArkExtractor"
name="PHOTO_INV_ARK"
label=""
inputRecordFilter=""
dataJoinSeparator="|"
dataMultiValueSeparator="|"
dataMultMaxi="1"
dataBefore="${flora-url}/ark:"
dataDefValue=""
dataAfter="/low"/>
</linked_field>
résultat obtenu.. avec un clic sur le lien ark exporté
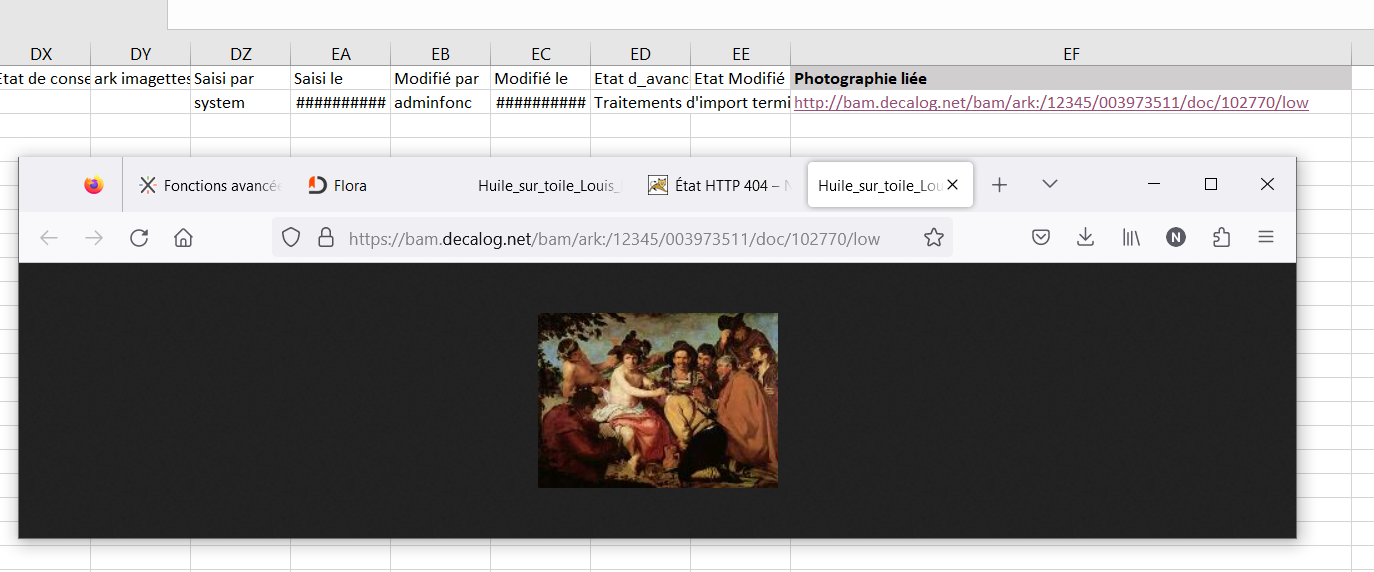
Avec Excel vous pouvez utiliser ce lien ark pour intégrer l'image dans la cellule si vous le souhaitez, mais ce n'est pas automatique. le plus simple est de procéder par copie d'écran partielle
- Touche Impr Ecran de votre ordinateur,
- selection de la zone image à copier,
- puis Edition/coller dans la cellule de votre choix
SI aprés avoir appuyé sur Impr Ecran vous ne pouvez pas selectionner une zone à l'écran, utilisez un outil de capture. dans le présent arcticle nous avons utilisé le freeware Screenpresso
Note ! La ligne excel ne s'agrandit pas toute seule, à vous de le faire pour garder une bonne lisibilité. Dans Excel, si vous triez les lignes, les images ainsi collées vont suivre (mais pas dans calc de Libre office)